2.4.4. 采用Q-learning 算法进行智能体路径规划#
Q-leaning算法介绍
Q-learning是强化学习中的一种基本的基于价值的算法,它以上述所说的贝尔曼最优方程、最优价值函数和时序差分学习为基础。智能体通过与环境的交互和学习,调整智能体本身的行为以适应环境。Q-leaning的伪代码如下表所示。Q(s,a)是在某个状态s下,选择动作a能够获得的奖励期望,环境会根据智能体的动作反馈相应的奖励R,Q-Table则是Q(s,a)奖励期望的集合表格。在Q-table中,表格的列为可选择的动作a,表格的行为不同的状态s。Q-table用于指引智能体在不同的状态s下,选择最合适的动作a。Q-leaning算法的主要思想就是将状态s与动作a构建成一张Q-table来存储Q(s,a),然后根据Q(s,a)来选取能够获得最大奖励的动作。
输入:学习率α∈[0,1]、学习次数 episode、折扣因子γ∈[0,1]
输出:Q*
1对所有s∈S、a∈A,初始化所有状态动作对下的表项Q(s,a), Q(terminal)=0
2for i<1 to episode do
3 初始化S
4 while S != terminal
5 根据现有的Q(s,)、当前状态(s)和对应的策略,选择一个动作(a)
6 执行动作(a)并观测产生的状态(s’)和奖励(r’)
7 更新Q(s,a): Q(s,a) Q(s,a)+α[rt+1+γmaxQ’(s’,a’)-Q(s,a)]
8 令s=s’
9 end while
10end for
智能体在选择并执行动作(at)之后,会通过与环境的交互得到相应的奖励(rt+1),并通过使用时序差分学习公式 (2-70) 更新Q(s,a):
其中Qt+1(st,at)是在状态st下选择动作a更新的奖励期望Q值,Qt(st,at)是在状态s下选择动作a的原奖励期望Q值;α是学习率,α∈[0,1],rt+1在状态st下选择并执行动作at返回的奖励,γ是衰减率,用以衡量未来奖励对当前的影响,γ∈[0,1], 是在新的状态st+1下所有可选择的动作at+1的最大奖励期望Q值。
在强化学习算法Q-learning中,智能体的目标是最大化累计折扣期望,即:
其中rt是在t时刻下采用动作at得到的奖励。
创建强化学习环境
为了成功实施强化学习,我们需要定义强化学习的另一个重要模块:环境(Environment)。强化学习的环境可以是一个网格,其中每个状态对应于二维网格上的一个图块,智能体可以采取的唯一动作是在网格向上、向下、向左或向右移动。智能体的目标是找到以最直接的方式通往目标方块的方法。
假设我们有一个 4×10 的网格,起始位置在左下方,目标位置在右下方。这两者之间的每一块网格都是“悬崖”,如图2-73。如果智能体进入悬崖,他们将获得 -100 奖励并被送回起始位置。而进入悬崖以外的每个网格都会产生 -1 奖励。在这些条件约束下,可获得的最大奖励是 -11(-1 上,-9 右,-1 下)。使用负奖励是鼓励智能体尽快移动并寻找目标状态。我们可以采用以下代码实现上述步骤。
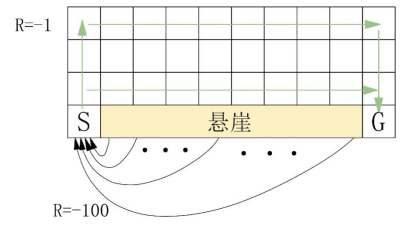
图2-73 创建强化学习环境#
1class CliffWorld:
2 """
3 40个状态 (4x10格子世界)
4 状态到网格的映射如下:
5 30 31 32 ... 39
6 20 21 22 ... 29
7 10 11 12 ... 19
8 0 1 2 ... 9
9 状态0为起点(S),状态9为目标点(G)
10 动作0、1、2、3分别对应右、上、左、下
11 从状态9(目标点G)走出去即结束会话
12 状态11-18执行动作3将掉入悬崖并返回状态0,同时获得-100的奖励
13 在非目标点的任何状态将获得-1的奖励
14 在边界处向边界外移动将保持原地
15 """
16
17 def __init__(self):
18 # 世界名称
19 self.name = "cliff_world"
20 # 状态数
21 self.n_states = 40
22 # 动作数
23 self.n_actions = 4
24 # x 轴维度
25 self.dim_x = 10
26 # y 轴维度
27 self.dim_y = 4
28 # 初始状态
29 self.init_state = 0
30
31 def get_outcome(self, state, action):
32 """
33 定义智能体的动作和状态更新函数
34 :param state:
35 :param action:
36 :return:
37 """
38 # 智能体进入状态9(目标点),本轮结束,奖励为0
39 if state == 9:
40 reward = 0
41 next_state = None
42 return next_state, reward
43
44 # 默认奖励为-1,使得智能体寻找最短路径以获得最大奖励
45 reward = -1
46 # 动作0位向右移动,状态+1
47 if action == 0:
48 next_state = state + 1
49 # 当智能体到达右边界,状态保持不变
50 if state % 10 == 9:
51 next_state = state
52 # 当智能体进入悬崖,本轮结束,奖励为-100
53 elif state == 0:
54 next_state = None
55 reward = -100
56 # 动作0为向上移动,状态+10
57 elif action == 1:
58 next_state = state + 10
59 # 智能体到达上边界,状态保持不变
60 if state >= 30:
61 next_state = state
62 elif action == 2:
63 next_state = state - 1
64 if state % 10 == 0:
65 next_state = state
66 elif action == 3:
67 next_state = state - 10
68 if 11 <= state <= 18:
69 next_state = None
70 reward = -100
71 elif state <= 9:
72 next_state = state
73 else:
74 print("Action must be between 0 and 3.")
75 next_state = None
76 reward = None
77 return int(next_state) if next_state is not None else None, reward
78
79 def get_all_outcomes(self):
80 """
81 定义环境输出的状态和奖励
82 :return:
83 """
84 outcomes = {}
85 # 遍历所有的状态动作对,得到特定状态下采取特定动作得到的状态和奖励。
86 # 该方法将为每个状态-动作对添加一个条目,
87 # 其中键是状态和动作的元组,
88 # 值是包含(1,next_state,reward)元组的列表。
89 # 所有条目都添加完后,该方法返回outcomes字典
90 for state in range(self.n_states):
91 for action in range(self.n_actions):
92 next_state, reward = self.get_outcome(state, action)
93 outcomes[state, action] = [(1, next_state, reward)]
94 return outcomes
Epsilon贪心策略
定义了环境之后,我们还需要定义智能体在环境中的动作决策策略。在本文中,我们使用最常见的Epsilon贪心策略。智能体的训练过程是一个平衡探索策略(Exploration)与利用策略(Exploitation)的过程。为了增加对当前环境的了解,智能体尝试之前没有执行过的动作以希望发现超过当前最优行为所获得的奖励,即探索策略。利用策略是智能体倾向采取根据历史经验学习到的获得最大奖励的动作。智能体的目标是最大化累计折扣期望,但如果智能体只采用利用策略,则智能体很可能陷入局部最优解,因为可能存在更好的动作策略没有被智能体发现。因此在Q-learning算法中,采用叫做Epsilon贪心策略,其中ε∈(0,1),该策略的本质是:智能体每次有1-ε的概率进行探索,即随机选择当前可用的所有动作,有ε的概率利用已学习的经验,即选择贪心动作a=argmaxa∈AQ(s,a)。
1import numpy as np
2
3
4def epsilon_greedy(q: np.ndarray, epsilon: float) -> int:
5 """
6 Epsilon贪心策略: 以概率(1-epsilon)选择最大值动作,以epsilon概率随机选择
7 :param q: 动作值的数组
8 :param epsilon:随机选择动作的概率
9 :return:选择的动作
10 """
11 # 以概率(1-epsilon)选择最大值动作
12 if np.random.random() > epsilon:
13 action = np.argmax(q)
14 else:
15 # 以 epsilon 概率随机选择动作
16 action = np.random.choice(len(q))
17
18 return action
创建训练函数
定义了环境和动作决策策略之后,我们还需要定义智能体在环境中训练策略,即如何训练智能体与环境交互来得到最优策略。我们使用Q-learning作为智能体的学习策略,Q-learning的具体实施会在下一节中讲解。本节侧重总体训练框架的搭建。训练函数(learn_environment)用于让智能体在给定的环境中学习。它有五个参数:env是环境对象,learning_rule是学习规则函数,params是参数字典,max_steps是每个episode最多的步数,n_episodes是学习的episode数。该函数会初始化Q-table,并使用 Epsilon贪心策略选择下一个动作。在每一步中,函数会根据当前状态和采取的动作来更新Q-table。在每个 episode 结束后,函数会记录该 episode 的总奖励。最终,函数返回训练后的Q-table和所有 episode 的总奖励。
1from typing import Tuple
2
3import numpy as np
4
5from chapter_2_4_4_02 import epsilon_greedy
6
7
8def learn_environment(env, learning_rule, params, max_steps: int,
9 n_episodes: int) -> Tuple[np.ndarray, int]:
10 """
11 以概率(1-epsilon)选择最大值动作,以epsilon概率随机选择
12 :param env: 环境对象,特指CliffWorld
13 :param learning_rule:一个基于观察更新价值函数的函数
14 :param params:学习规则和探索策略中使用的参数字典
15 :param max_steps:代表智能体在一个训练过程中可以采取的最大步数
16 :param n_episodes:用于训练的代数
17 :return:更新后的Q价值函数,shape 为(n_states, n_actions) 和 训练过程的总奖励数
18 """
19 # 初始化Q-table,创建一维数组(env.n_states, env.n_actions)且元素值均为1
20 value = np.ones((env.n_states, env.n_actions))
21 # 开始智能体学习过程
22 reward_sums = np.zeros(n_episodes)
23 # 开始训练循环
24 for episode in range(n_episodes):
25 # 初始化状态
26 state = env.init_state
27 reward_sum = 0
28 for t in range(max_steps):
29 # 根据epsilon贪心策略选择下一个动作
30 action = epsilon_greedy(value[state], params['epsilon'])
31 # 观察采取的动作得到的环境反馈
32 next_state, reward = env.get_outcome(state, action)
33 # 更新Q-table数值
34 value = learning_rule(state, action, reward, next_state,
35 value, params)
36 # 计算总奖励
37 reward_sum += reward
38 # 定义训练终止条件
39 if next_state is None:
40 break
41 state = next_state
42 # 记录每一次训练过程的总奖励
43 reward_sums[episode] = reward_sum
44
45 return value, reward_sums
创建Q-learning 函数
定义完总体训练框架之后,我们需要具体实施Q-learning算法。在Q-learning中采用时序差分更新方法,即智能体每执行一个动作更新一次策略,进行单步更新。根据时序差分算法公式(2-70)得到Q值的更新公式:
定义时间差分误差(Temporal Difference Error):
1from typing import Dict
2
3import numpy as np
4
5
6def q_learning(state: int, action: int, reward: float, next_state: int,
7 value: np.ndarray, params: Dict):
8 """
9 Q-learning
10
11 Args:
12 state: 当前状态标识符
13 action: 执行的动作
14 reward: 接收到的奖励
15 next_state: 转换到的状态标识符
16 value: 当前价值函数,形状为(n_states, n_actions)
17 params:默认参数字典
18
19 Returns:
20 更新后的价值函数,形状为(n_states, n_actions)
21
22 """
23 # 当前状态-动作对的q值
24 q = value[state, action]
25 # 找到下一个状态的最大Q值
26 if next_state is None:
27 max_next_q = 0
28 else:
29 max_next_q = np.max(value[next_state])
30 # 计算时序差分 TD error
31 td_error = reward + params['gamma'] * max_next_q - q
32 # 更新Q值
33 value[state, action] = q + params['alpha'] * td_error
34
35 return value
创建绘图函数
我们已经完成了Q-learning 算法的大部分,为了使得强化学习的训练过程更加直观,接下来我们将创建几个绘图函数用于对强化学习的训练过程和结果进行可视化。
plot_state_action_values函数用于绘制每个状态下每个动作的价值。它接受环境Environment和Q-table作为参数,并使用折线图显示每个状态下每个动作的价值。
plot_quiver_max_action函数用于绘制每个状态的最大价值动作或最大概率动作。它接受环境和Q-table作为参数,并显示每个状态的最大价值或最大概率动作。
plot_rewards函数用于生成显示每个训练过程的智能体累积总奖励。
1import numpy as np
2from matplotlib import pyplot as plt
3from scipy.signal import convolve as conv
4
5
6def plot_state_action_values(env, value, ax=None):
7 """
8 可选参数,表示绘图将生成的坐标轴。如果不提供,将创建一个新的图形和坐标轴。
9
10 Args:
11 env: 环境对象
12 value: Q-table,表示为形状为 (n_states, n_actions) 的数组
13 ax: 可选参数,表示绘图将生成的坐标轴。如果不提供,将创建一个新的图形和坐标轴。
14
15 Returns:
16
17 """
18 if ax is None:
19 fig, ax = plt.subplots()
20
21 for a in range(env.n_actions):
22 ax.plot(range(env.n_states), value[:, a],
23 marker='o', linestyle='--')
24 ax.set(xlabel='States', ylabel='Values')
25
26 ax.legend(['R', 'U', 'L', 'D'], loc='lower right')
27
28
29def plot_quiver_max_action(env, value, ax=None):
30 """
31 生成在每个状态下显示最大价值或最大概率动作
32
33 Args:
34 env: 环境对象
35 value: Q-table,表示为形状为 (n_states, n_actions) 的数组。
36 ax: 可选参数,表示绘图将生成的坐标轴。如果不提供,将创建一个新的图形和坐标轴。
37
38 Returns:
39
40 """
41 if ax is None:
42 fig, ax = plt.subplots()
43
44 big_x = np.tile(np.arange(env.dim_x), [env.dim_y, 1]) + 0.5
45 big_y = np.tile(np.arange(env.dim_y)[::-1][:, np.newaxis],
46 [1, env.dim_x]) + 0.5
47 which_max = np.reshape(value.argmax(axis=1), (env.dim_y, env.dim_x))
48 which_max = which_max[::-1, :]
49 big_u = np.zeros(big_x.shape)
50 big_v = np.zeros(big_x.shape)
51 big_u[which_max == 0] = 1
52 big_v[which_max == 1] = 1
53 big_u[which_max == 2] = -1
54 big_v[which_max == 3] = -1
55
56 ax.quiver(big_x, big_y, big_u, big_v)
57 ax.set(
58 title='Maximum value/probability actions',
59 xlim=[-0.5, env.dim_x + 0.5],
60 ylim=[-0.5, env.dim_y + 0.5],
61 )
62 ax.set_xticks(np.linspace(0.5, env.dim_x - 0.5, num=env.dim_x))
63 ax.set_xticklabels(["%d" % x for x in np.arange(env.dim_x)])
64 ax.set_xticks(np.arange(env.dim_x + 1), minor=True)
65 ax.set_yticks(np.linspace(0.5, env.dim_y - 0.5, num=env.dim_y))
66 # code too long in a line
67 y_tick_labels = np.arange(0, env.dim_y * env.dim_x, env.dim_x)
68 ax.set_yticklabels(list(map(lambda x: str(int(x)), y_tick_labels)))
69 ax.set_yticks(np.arange(env.dim_y + 1), minor=True)
70 ax.grid(which='minor', linestyle='-')
71
72
73def plot_heatmap_max_val(env, value, ax=None):
74 if ax is None:
75 fig, ax = plt.subplots()
76
77 if value.ndim == 1:
78 value_max = np.reshape(value, (env.dim_y, env.dim_x))
79 else:
80 value_max = np.reshape(value.max(axis=1), (env.dim_y, env.dim_x))
81 value_max = value_max[::-1, :]
82
83 im = ax.imshow(value_max,
84 aspect='auto',
85 interpolation='none',
86 cmap='afmhot')
87 ax.set(title='Maximum value per state')
88 ax.set_xticks(np.linspace(0, env.dim_x - 1, num=env.dim_x))
89 ax.set_xticklabels(["%d" % x for x in np.arange(env.dim_x)])
90 ax.set_yticks(np.linspace(0, env.dim_y - 1, num=env.dim_y))
91 if env.name != 'windy_cliff_grid':
92 y_tick_labels = np.arange(0, env.dim_y * env.dim_x, env.dim_x)
93 ticks_after_handle = list(map(lambda x: str(int(x)), y_tick_labels))
94 ax.set_yticklabels(ticks_after_handle[::-1])
95 return im
96
97
98def plot_rewards(n_episodes, rewards, average_range=10, ax=None):
99 """
100 生成显示每个训练过程的累积的总奖励
101
102 Args:
103 n_episodes: 智能体训练次数
104 rewards: 训练过程智能体获得的总奖励
105 average_range: 用于平滑奖励曲线的参数
106 ax: 可选参数,表示绘图将生成的坐标轴。如果不提供,将创建一个新的图形和坐标轴。
107
108 Returns:
109
110 """
111 if ax is None:
112 fig, ax = plt.subplots()
113
114 smoothed_rewards = (conv(rewards, np.ones(average_range), mode='same')
115 / average_range)
116
117 ax.plot(range(0, n_episodes, average_range),
118 smoothed_rewards[0:n_episodes:average_range],
119 marker='o',
120 linestyle='--')
121 ax.set(xlabel='Episodes', ylabel='Total reward')
122
123
124def plot_performance(env, value, reward_sums, n_episodes: int):
125 """
126 调用定义的画图函数,生成强化学习训练过程和结果的可视化
127 Args:
128 env: 环境对象
129 value: Q-table,表示为形状为 (n_states, n_actions) 的数组
130 reward_sums: 训练过程智能体获得的总奖励
131 n_episodes: 训练总次数
132
133 Returns:
134
135 """
136 fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(16, 12))
137 plot_state_action_values(env, value, ax=axes[0, 0])
138 plot_quiver_max_action(env, value, ax=axes[0, 1])
139 plot_rewards(n_episodes, reward_sums, ax=axes[1, 0])
140 im = plot_heatmap_max_val(env, value, ax=axes[1, 1])
141 fig.colorbar(im)
142
143 fig.savefig('results_figure.png', dpi=300)
强化学习训练与结果可视化
最后,我们将定义的各函数合并起来,首先定义强化学习的参数包括贪心率,学习率和折扣因子。接着定义强化学习训练总次数和每次训练的尝试次数,并对环境进行初始化。紧接着进行强化学习的训练并可视化训练过程和结果。
1import numpy as np
2import matplotlib
3
4from chapter_2_4_4_01 import CliffWorld
5from chapter_2_4_4_04 import q_learning
6from chapter_2_4_4_05 import plot_performance
7from chapter_2_4_4_03 import learn_environment
8
9matplotlib.rcParams['font.sans-serif'] = ['SimHei']
10matplotlib.rcParams['font.family'] = 'sans-serif'
11matplotlib.rcParams['axes.unicode_minus'] = False
12
13np.random.seed(1)
14
15params = {
16 'epsilon': 0.1,
17 'alpha': 0.1,
18 'gamma': 1.0,
19}
20
21n_episodes = 500
22max_steps = 1000
23
24env = CliffWorld()
25
26results = learn_environment(env, q_learning, params, max_steps, n_episodes)
27value_qlearning, reward_sums_qlearning = results
28
29plot_performance(env, value_qlearning, reward_sums_qlearning, n_episodes)
我们观察本案例中强化学习的可视化结果,下面三幅图分别显示了智能体学习过程的不同方面。(a)图是Q-table数值的可视化表示,显示了不同状态下不同动作的期望值。值得注意的是,从初始状态开始,如果智能体向下走,Q-table的期望值很低,说明智能体意识到进入悬崖会得到惩罚,并尝试避开悬崖。图(b)显示了基于Q-table的Epsilon贪心策略,即如果智能体仅在该状态下进行最佳预测,它会采取什么行动。我们会发现智能体学到了在起点往上走,继而往右走,最后往下走绕开悬崖的策略。图(c)是智能体学习的实际证明,我们可以看到总奖励随着训练过程稳步增加,直到渐近于最大可能的奖励-11。
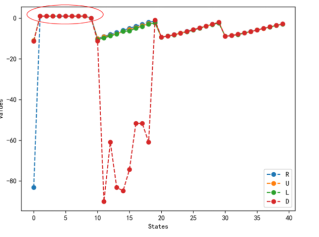
(a) Q-table数值的可视化#
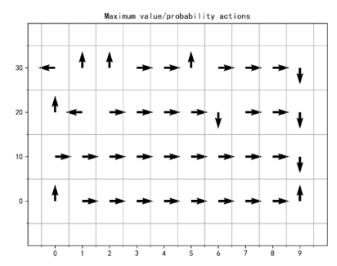
(b) 基于Q-table的贪心策略学习到的最优动作)#
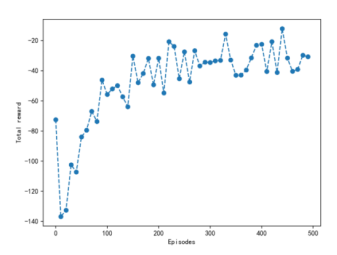
(c) 智能体训练过程的总奖励#
Q-learning完整代码可参考附录或扫描二维码下载。
待处理
真实Q-learing 代码线上路径