3.3.1. 数据集制作#
数据的获取可来源于多种途径,包括自己实地采集、网络收集和公共数据集。我们选择来源于kaggle官网的裂缝数据[9],该数据包含桥面、道路和墙面三个场景下有无裂缝的图片。查看图像数据如图3-8所示。





下载的图片总量为56092,各类别图片数量和分布如图3-9所示。
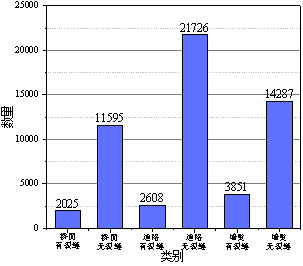
图 3-9 各类别图片数量和分布#
为了方便程序读取图片数据和制作标签,我们首先需要将下载的数据按不同类别单独储存在文件夹中。我们在根目录新建文件夹datasets,并按照下图所示对文件夹进行分级和分类。在根目录下有三个一级子目录,分别代表桥面、道路和墙面三个场景,二级子目录分别是对应场景下有无裂缝的文件夹,在二级子文件夹下存放图片,具体存放格式如图3-10所示。
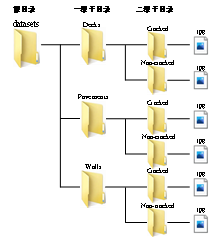
图3-10 图片数据储存方式#
将数据存入文件夹之后,接下来需要制作可以直接用于训练的数据集。一共分为三个步骤:1. 读取图片地址和制作标签,并将图片地址和标签存于同一列表下;2. 创建数据集,将图片划分为训练集和测试集后,读取图片并进行预处理;3. 创建DataLoader,设置batch_size,定义从数据集中读取数据的方式。下面我们逐步讲解如何将下载的数据处理成用于训练的数据集。
(1)读取数据路径与制作标签
我们的目标是将所有图片的路径存储到列表data_x内,并将该列表中每个地址对应的标签存储到列表data_y,同时还要将六个类别的标签名存入列表class_name_s。这里需要注意的是,标签和标签名是两个内容。标签是0, 1, 2, 3, 4, 5的数字编号,用于六分类任务,而标签名是类别的名称。我们通过以下程序来实现我们目标。
1import os
2
3# 读取数据路径与制作标签>
4IMAGE_DATASET_PATH = os.path.join(
5 "..", "data", "datasets"
6)
7# 存储标签名
8class_name_s = []
9# 存储图片地址和标签
10data_set = []
11
12for parent_class_name in os.listdir(IMAGE_DATASET_PATH):
13 # 返回(路径)下所有文件夹名, ['Decks', 'Pavements', 'Walls']
14 for sub_class_name in os.listdir(os.path.join(IMAGE_DATASET_PATH,
15 parent_class_name)):
16 # 拼接路径,例如:datasets\Decks返回路径下所有文件夹名
17 class_name = ".".join([parent_class_name, sub_class_name])
18 # 返回parent_class_name.sub_class_name作为标签名
19
20 # 返回class_name_s列表长度
21 class_i = len(class_name_s)
22 # 将标签名存入class_name_s
23 class_name_s.append(class_name)
24 # 存储图片路径
25 data_x = []
26 # 存储图片标签
27 data_y = []
28 for sub_data_file_name in os.listdir(
29 os.path.join(IMAGE_DATASET_PATH,
30 parent_class_name,
31 sub_class_name)):
32 # 遍历图片路径并存储在data_x
33 data_x.append(os.path.join(IMAGE_DATASET_PATH,
34 parent_class_name,
35 sub_class_name,
36 sub_data_file_name))
37 # 将标签存储在data_y
38 data_y.append(class_i)
39 # 整合图片路径列表和标签列表
40 data_set.append((data_x, data_y))
我们遍历每一个图片的地址,并将其地址存储在列表中。首先打开datasets文件夹,依次遍历一级子目录,parent_class_name对应一级子目录的三个场景文件名。接着按顺序打开一级子目录,依次遍历二级子目录,sub_class_name对应二级子目录的有无裂缝文件名。最后按顺序打开二级子目录,依次遍历文件夹内的图片,sub_data_file_name对应图片名。值得注意的是,标签由class_name_s的长度决定,而class_name_s只有遍历完一个类别的所有图片后才会有新的类别名加入。初始class_name_s为空列表,len(class_name_s)= 0,所以在遍历Decks\Cracked文件夹下的图片时,标签都为0。当循环到二级子目录Decks\Non-cracked,列表class_name_s内只存储了一个文件名Decks.Cracked,此时len(class_name_s)= 1,所以遍历Decks\Non-cracked文件夹下的图片时,标签都为1。直至循环结束,六个类别的图片分别对应的标签为0, 1, 2, 3, 4, 5。我们看一下这些列表里存储的值。
print(class_name_s)
['Decks.Cracked', 'Decks.Non-cracked', 'Pavements.Cracked', 'Pavements.Non-cracked', 'Walls.Cracked', 'Walls.Non-cracked']
print(data_set)
[
(['..\\data\datasets\\Decks\\Cracked\\7001-115.jpg',…],[0,0,0,…]), (['datasets\\Decks\\Non-cracked\\7001-1.jpg',…],[1,1,1,…]),
(['..\\data\datasets\\Pavements\\Cracked\\001-100',…],[2,2,2,…]),
(['..\\data\datasets\\Pavements\\Non-cracked\\001-1.jpg',…],[3,3,3,…]),
(['..\\data\datasets\\Walls\\Cracked\\7069-101.jpg',…],[4,4,4,…]),
(['..\\data\datasets\\Walls\\Non-cracked\\7069-1.jpg',…],[5,5,5,…])
]
(2)创建数据集
通过上述步骤,我们已经把图片地址和标签存储到列表data_set,接下来需要读取图片信息并制作数据集。首先,将所有数据划分为训练集和测试集,接着定义图像预处理函数,最后读取图片并处理后储存。创建过程如下:
1import random
2
3import numpy as np
4from sklearn import model_selection
5
6from chapter_3_3_1_01 import data_set, class_name_s
7
8# 用来存储训练集图片路径
9x_train_s = []
10# 用来存储测试集图片路径
11x_test_s = []
12# 用来存储训练集标签
13y_train_s = []
14# 用来存储测试集标签
15y_test_s = []
16for x_data, y_data in data_set:
17 # 每个类别的所有图片路径和标签按8:2分为训练集和测试集,训练标签和测试标签
18 x_tr, x_te, y_tr, y_te = model_selection.train_test_split(x_data,
19 y_data,
20 test_size=0.2)
21 # 六个类别的训练集路径依次存入x_train_s
22 x_train_s.extend(x_tr)
23 # 六个类别的测试集路径依次存入x_test_s
24 x_test_s.extend(x_te)
25 # 六个类别的训练标签依次存入y_train_s
26 y_train_s.extend(y_tr)
27 # 六个类别的测试标签依次存入y_test_s
28 y_test_s.extend(y_te)
29# 可以发现,上述划分训练集和测试集时并不是对整个数据按照比例进行划分,
30# 而是对每个类别分别进行划分后合并,这样做可以提高每个类别训练样本的均匀性。
31# print(len(x_train_s)) = 44871, 训练集的数量约为总数的8/10。
32
33train_data = list(zip(x_train_s, y_train_s))
34# 将训练集和训练标签合并—>[('图片地址1', 标签1),……('图片地址44871', 标签44871)]
35random.shuffle(train_data)
36# 将列表中元素顺序打乱
37x_train_s, y_train_s = list(zip(*train_data))
38# 将打乱后的训练数据拆分成新的训练集和训练标签
39# 对测试集路径做相同的打乱和拆分处理
40test_data = list(zip(x_test_s, y_test_s))
41random.shuffle(test_data)
42x_test_s, y_test_s = list(zip(*test_data))
43# 保存训练集和测试集数据量
44dataset_sizes = {
45 "train": len(train_data),
46 "val": len(test_data),
47}
48
49# 计算样本权重,可以得到每个样本所占比重,是后续设置损失函数时所需参数
50# 将训练集标签转为数组
51y_train_np = np.asarray(y_train_s)
52# 将训练集标签数组转为独热编码
53y_one_hot = np.eye(len(class_name_s))[y_train_np]
54# 列向量求和,可知道训练集中各类别的数量
55class_count = np.sum(y_one_hot, axis=0)
56# 求六个类别总数量—>44871
57total_count = np.sum(class_count)
58# 求样本权重
59label_weight = (1 / class_count) * total_count / 2
这一步我们将data_set内的图片按照8:2划分为训练集和测试集,对应的标签划为训练标签和测试标签。各部分对应的数据量可以通过以下程序查看。
print("训练集数据量:" + str(len(x_train_s)))
print("测试集数据量:" + str(len(x_test_s)))
训练集数据量:44871
测试集数据量:11221
接下来,根据图片地址读取图片信息,读取时我们首先加载用于图像预处理的功能函数transforms.Compose()对图片进行预处理,预处理可以将图片转变为网络模型输入的尺寸,也可以对图片进行翻转、剪切和颜色变化等操作来增强数据特征。
1from torchvision import transforms
2
3data_transforms = {
4 'train': transforms.Compose([
5 # 调整图片尺寸—>[224, 224]
6 transforms.Resize((224, 224)),
7 # 随机图片灰度化
8 transforms.RandomGrayscale(p=0.1),
9 # 随机仿射变化
10 transforms.RandomAffine(0, shear=5, scale=(0.8, 1.2)),
11 # 图片属性变换
12 transforms.ColorJitter(brightness=(
13 0.5, 1.5), contrast=(0.8, 1.5), saturation=0),
14 # 随机图片水平翻转
15 transforms.RandomHorizontalFlip(),
16 # 将图片格式转换为张量
17 transforms.ToTensor(),
18 # 图片归一化
19 transforms.Normalize(mean=[0.485, 0.456, 0.406],
20 std=[0.229, 0.224, 0.225]),
21 ]),
22 # 测试集图片预处理,只进行图片尺寸、格式和归一化处理
23 'val': transforms.Compose([
24 transforms.Resize((224, 224)),
25 transforms.ToTensor(),
26 transforms.Normalize(mean=[0.485, 0.456, 0.406],
27 std=[0.229, 0.224, 0.225]),
28 ]),
29}
我们在这里只使用了部分图片预处理函数,其他预处理函数的详细用法读者可以自行学习和使用。接下来,我们将进行图片信息的读取与存储。
1from PIL import Image
2
3from torch.utils import data as torch_data
4
5from chapter_3_3_1_03 import data_transforms
6from chapter_3_3_1_02 import x_train_s, y_train_s, x_test_s, y_test_s
7
8
9class CrackDataset(torch_data.Dataset):
10 """
11 定义一个读取图片信息的类
12 """
13 _files = None
14 _labels = None
15 _transform = False
16
17 def __init__(self, abs_file_path_s, y_datas, trans=False):
18 """
19
20 Args:
21 abs_file_path_s:
22 y_datas:
23 trans: 该数据集可以使用的数据增强方式集
24 """
25 self._files = abs_file_path_s # 传入图像地址
26 self._labels = y_datas # 传入图像标签
27 self._transform = trans # 传入需要载入的预处理函数
28
29 def __getitem__(self, item):
30 """
31 通过python 魔法方法扩写,使其呈现出列表,按索引取值的功能,时间换空间,避免内存爆炸
32 Args:
33 item:
34
35 Returns:
36
37 """
38 img = Image.open(self._files[item]).convert("RGB")
39 # 按顺序读取图片标签
40 label = self._labels[item]
41 if self._transform:
42 # 对图片进行预处理or增强
43 img = self._transform(img)
44 # 返回预处理后的图像信息和标签
45 return img, label
46
47 def __len__(self):
48 """
49 返回数据长度;同属于python 魔法方法扩写,用于支持len()函数调用
50 Returns:
51
52 """
53 return len(self._files)
54
55
56train_data = CrackDataset(abs_file_path_s=x_train_s, y_datas=y_train_s,
57 trans=data_transforms["train"]) # 调用类功能,输出训练数据
58test_data = CrackDataset(abs_file_path_s=x_test_s, y_datas=y_test_s,
59 trans=data_transforms["val"]) # 调用类功能,输出测试数据
这一步我们依据图片路径读取了图片,同时还将训练图片和训练标签存入了train_data,测试图片和测试标签存入了test_data,并对图片进行了预处理。
(3)创建数据加载器DataLoader
上一步我们已经将所有图片信息和标签信息读取并存储在train_data和test_data,下一步将定义如何从train_data和test_data中抓取图片到网络模型中进行训练和测试。我们使用torch_data.DataLoader( )构建可迭代的数据装载器,使用超参数batch_size确定网络模型一次读入的图片数量。
1from torch.utils import data as torch_data
2
3from chapter_3_3_1_04 import train_data, test_data
4
5# 一次输入网络模型的图片量,根据开发环境GPU 大小调整
6BATCH_SIZE = 64
7train_loader = torch_data.DataLoader(train_data, batch_size=BATCH_SIZE,
8 shuffle=True)
9test_loader = torch_data.DataLoader(test_data, batch_size=BATCH_SIZE)
10
11# 将训练数据和测试数据存入字典dataloaders
12dataloaders = {
13 'train': train_loader,
14 'val': test_loader,
15}
通过上述三个步骤,我们完成了数据集制作的全过程。接下来,我们便可以开始进行网络的构建与训练了!