4.3.4. 最小二乘损失#
DCGAN主要是对生成器和判别器的架构进行改进,利用一些先进模块的优越性能提升了模型性能。但在生成对抗网络的学习过程中,需要着重关注对生成器与判别器性能的平衡,不能一强一弱。而平衡生成器与判别器强弱的关键部分就是损失函数。
DCGAN使用的交叉熵损失函数会使被判别器判别为真但仍远离真实数据的生成样本停止迭代,因为这些生成样本已经成功欺骗了判别器,更新生成器时便会出现梯度消失的问题。换句话说,因为判别器已经对样本进行了正确的分类,此时的损失已经很小,判别器产生的梯度也非常小,故在后续的训练过程中,几乎不会再对这部分样本的模型参数进行更好的更新。
最小二乘损失函数能够惩罚距离决策边界太远的生成样本。因为要使最小二乘损失更小,需将距离决策边界太远的生成样本拉向决策边界。随着模型的不断训练,生成样本便会更趋近于真实样本。因此我们尝试将DCGAN的交叉熵损失函数替换为最小二乘损失函数,看看是否有改进效果。两种损失函数的决策行为如图4-12所示。
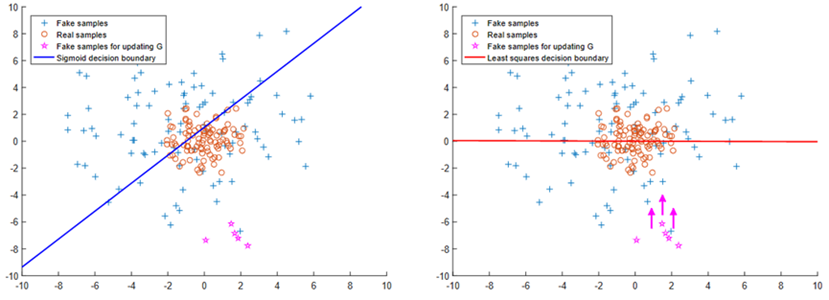
图4-12中蓝色线为交叉熵损失函数的决策边界,红色线为最小二乘损失函数的决策边界。决策边界是一种划分空间的分割界面,决策边界同侧的所有数据点同属于同一类别。判别器就起到划分样本数据所属类别的决策作用。可以看到,左图中有许多距离真实样本较远的离群点,这部分样本很难再向决策边界靠近。若使用最小二乘损失函数进行训练,随着模型的迭代,距离决策边界较远的生成样本会被逐步拉向真实样本,使这些生成样本更加接近真实样本。
最小二乘损失函数的表达式如下:
采用最小二乘损失的训练时间约为187分钟,训练结果为图4-13右图,图4-13左图为未使用改进方法的训练结果。可以看到采用最小二乘损失后,生成样本的质量有一定提升。


基于PyTorch实现的代码如下:
# 最小二乘损失
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(in_channels=nc, out_channels=ndf,
kernel_size=4, stride=2, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=ndf, out_channels=ndf * 2,
kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=ndf * 2, out_channels=ndf * 4,
kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=ndf * 4, out_channels=ndf * 8,
kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Flatten(),
nn.Linear(8192, 1), # 全连接层
)
def forward(self, input):
return self.main(input)
首先我们需要将判别器最后一层替换为全连接层,不再使用Sigmoid激活函数。训练判别器时,先获得对真实样本的判别值D_real,然后使用torch.mean计算判别器对真实样本的最小二乘损失。随后,获得对生成样本的判别值D_fake,然后使用torch.mean计算判别器对生成样本的最小二乘损失。对两者求和,可得判别器的损失值errD。训练生成器时,获得判别器对生成样本的判别值DG_fake,然后使用torch.mean计算获得生成器的损失值errG。最后,利用该损失值更新模型。
# 最小二乘损失
for epoch in range(epochs):
for i, (data, _) in enumerate(dataloader):
b_size = data.shape[0]
data = data.to(device)
a = torch.ones(b_size, 1).to(device) # 判别器使用的真实数据标签
b = torch.zeros(b_size, 1).to(device) # 判别器使用的生成数据标签
c = torch.ones(b_size, 1).to(device) # 生成器使用的生成数据标签
# 用真实数据、real_label训练判别器
netD.zero_grad()
D_real = netD(data)
loss_D_real = 0.5 * torch.mean((D_real - a) ** 2) # 基于真实数据,计算判别器最小二乘损失
loss_D_real.backward()
D_x = D_real.mean().item()
# 用噪声生成的数据、fake_label训练判别器
noise = torch.randn(b_size, nz, 1, 1, device=device)
fake_data = netG(noise)
D_fake = netD(fake_data.detach())
loss_D_fake = 0.5 * torch.mean((D_fake - b) ** 2) # 基于生成数据,计算判别器最小二乘损失
loss_D_fake.backward()
D_G_z1 = D_fake.mean().item()
errD = loss_D_real + loss_D_fake # 判别器损失
optimizerD.step()
# 训练生成器
netG.zero_grad()
DG_fake = netD(fake_data)
errG = 0.5 * torch.mean((DG_fake - c) ** 2) # 计算生成器最小二乘损失
errG.backward()
optimizerG.step()
D_G_z2 = DG_fake.mean().item()