5.2.2. Q-learning算法#
在2.4.4小节中,我们已经介绍了Q-learning强化学习算法和贪心策略的基本原理,在此我们通过图表和举例进一步解释该算法。在Q-learning中,智能体通过与环境的交互和学习,调整智能体本身的行为以适应环境。Q-leaning的伪代码如算法5-1所示。Q( s,a) 是在某个状态s下,选择动作a能够获得的奖励期望,环境会根据智能体的动作反馈相应的奖励r,Q表格则是Q( s,a) 奖励期望的集合表格,如图5-6所示。在Q表格中,表格的列为可选择的动作a,表格的行为不同的状态s。Q-leaning算法的主要思想就是将状态s与动作a构建成一张Q表格来存储Q( s,a),通过与环境的交互对Q(s,a)进行估计,然后根据存储的Q(s,a)来选取能够获得最大的奖励的动作。
输入:学习率α∈[0,1]、学习次数 episode、折扣因子γ∈[0,1]
输出:学习到得 Q 表格
1对所有 s∈S、a ∈A,初始化所有状态动作对下的表项Q(s,a),Q(terminal,)=02:for i < 1 to episode do
2 初始化S
3 while S != terminal
4 根据现有的Q(s,·),当前状态(s)和对应的策略,选择一个动作(a)
5 执行动作(a)并观测产生的状态(s^')和奖励(r^')
6 更新Q(s,a):Q(s,a)←Q(s,a)+α[r_(t+1)+γmaxQ^' (s',a')-Q(s,a)]
7 令s=s’
8 end while
9end for
在强化学习算法Q-learning中,智能体的目标是最大化累计折扣期望:
其中,\(r_t\)是在t时刻下采用动作\(a_t\)得到的奖励,γ为折扣因子,用以衡量未来奖励对当前的影响,γ∈[0,1]。
Q 函数
Q函数[3, 4] 是通过当前智能体的状态(s)和动作(a)作为索引,在Q表格中找到对应的奖励期望。在智能体进行环境探索之前,Q表格通常随机进行赋值,也可均赋值为0。随着智能体对环境的探索,通过使用贝尔曼方程(Bellman Equation)(2-63)和时序差分算法(2-70),迭代更新Q(s,a) ,Q表格逐步收敛,可对智能体所处的环境有较为准确地评估,见公式(5-2)。
Q函数[3, 4]需要两个输入:状态(s)和动作(a),返回在该状态下选择该动作的奖励期望:
\[\begin{split} \begin{align} \begin{aligned} Q^π (s_t,a_t )&=E[r_{t+1} + γr_{t+2} + γ^2 r_{t+3} +⋯|s_t,a_t] \\ &=E[r_{t+1}+γ \max_{a_{t+1}} Q^π (s_{t+1},a_{t+1})|s_t,a_t ] \\ \end{aligned} \ \tag{5-2} \end{align} \end{split}\]其中,\(Q^π (s_t,a_t)\)是在状态\(s_t\)下选择动作\(a_t\)返回的奖励期望Q值,\(E(r_ {t+1} + γr_{t+2} + γ^2 r_{t+3} +⋯)\)是考虑未来折扣因子γ的奖励期望总和,\(s_t\)和\(a_t\)分别是当前的状态和动作。
初始化Q值
Q-Table通常被定义为一个m列(m=可选择的动作数),n行(n=状态数)的表格。假设智能体所在的环境可划分为64个格子,对应智能体的64种状态(n=64);同时,智能体有四种可选择的动作(m=4),那么此时Q-Table为64行,4列的表格,如图5-6所示。
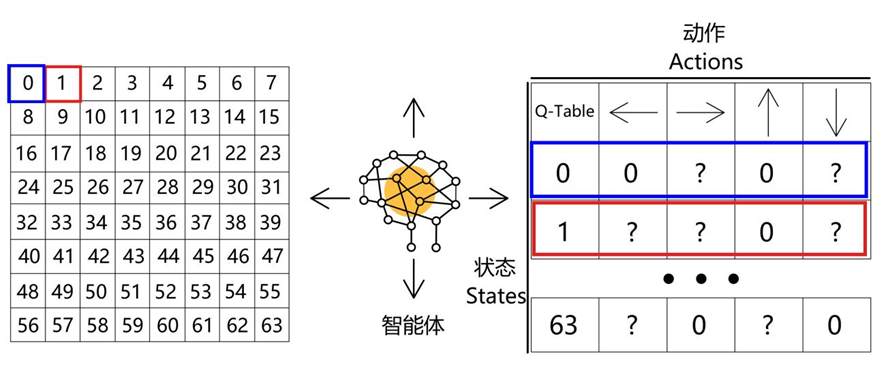 图 5-6 Q-Table 可视化
图 5-6 Q-Table 可视化
选择并执行动作
智能体会根据Q-Table中的奖励期望和当前的状态(s)选择动作(a)。智能体的训练过程可看做是一个如何平衡探索策略(Exploration)与利用策略(Exploitation)的问题[5] 。为了增加对当前环境的了解,智能体会尝试之前没有执行过的动作,目的是希望能够发现超过当前最优行为所获得的奖励的动作,即探索策略。利用策略是智能体倾向采取根据历史经验学习到的获得最大奖励的动作。智能体的目标是最大化累计折扣期望,但如果智能体只采用利用策略,则智能体很可能陷入局部最优解,因为智能体可能没有发现存在的更好的动作策略。
因此,在Q-learning算法中,可采用Epsilon贪心策略,其中ε∈(0,1) ,如图5-7所示,该策略的本质是:智能体每次有ε的概率进行探索,即随机选择当前可用的动作,有( 1-ε)的概率利用已学习的经验,即选择贪心动作a=〖argmax〗_(a∈A) Q(s,a) 。在任务的一开始,ε的数值通常设定为较高的数值,因为在一开始智能体对环境一无所知,智能体只能随机选择动作以探索环境。随着迭代训练的进行,ε会逐步降低,Q-Table逐渐收敛,即智能体对环境的了解越来越准确,逐渐倾向于利用已获得的经验进行动作的选择。
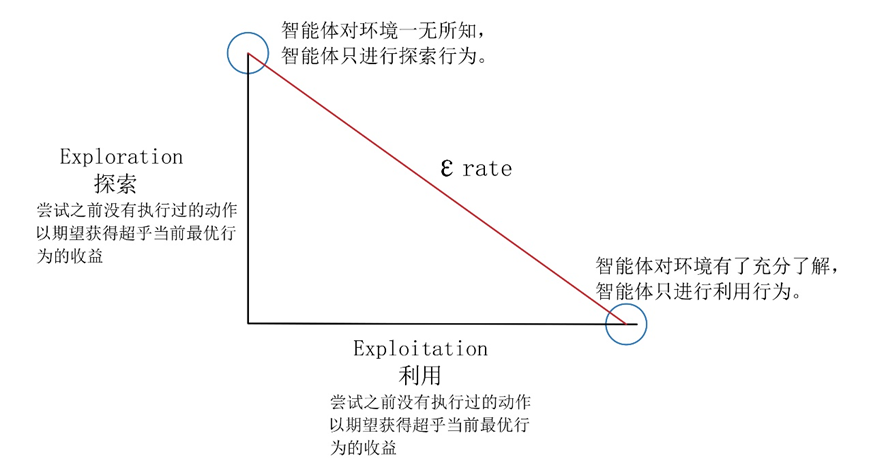 图 5-7 探索与利用的平衡
图 5-7 探索与利用的平衡
如图5-8所示,在训练过程的初期,智能体有较高的ε贪心率数值,倾向于采取随机动作。此时智能体选择向右的动作,与障碍物发生了碰撞,并根据5.3.1章节中智能体的奖惩模块得到惩罚-1分,紧接着根据得到的惩罚对Q-Table进行更新。Q-Table的更新方法将在下一小节进行详细介绍。
 图 5-8 Q-Table 更新
图 5-8 Q-Table 更新
评估奖励并更新Q-Table
智能体在选择并执行动作(a)之后,会通过与环境的交互得到相应的奖励(r),并通过贝尔曼方程(Bellman Equation)和时序差分(Temporal-Difference Learning)算法更新Q (s,a):
\[ Q_{t+1} (s_t,a_t )= Q_t (s_t,a_t ) +α[r_{t+1}+γ \max{a_{t+1}} Q_t(s_{t+1},a_{t+1})- Q_t(s_t,a_t)] \tag {5-3} \]其中,\(Q_{t+1} (s_t,a_t )\)是在状态s下选择动作a更新的奖励期望Q值; \(Q_t ( s_t,a_t )\)是在状态s下选择动作a的原奖励期望Q值; α是学习率,α∈[0,1];\(r_{t+1}\) 是在状态s下选择并执行动作a返回的奖励;γ是折扣因子,用以衡量未来奖励对当前的影响, γ∈[0,1]; \(\max_{a} Q_t (s_{t+1},a_{t+1})\)是在新的状态\(s_{t+1}\) 下所有可选择的动作\(a_{t+1}\)的最大奖励期望Q值。
假设此时的学习率α为0.1,折扣因子γ为0.9,如图5-8所示,智能体选择向右的动作,与障碍物发生了碰撞,得到惩罚-1分,让我们根据公式5-3更新Q ( s,a)。
\[\begin{split} \begin{align} \begin{aligned} New Q(状态(s)&:0,动作(a):向右)\\ &=Q(状态(s):0,动作(a):向右)+α[ΔQ(状态(s):0,动作(a):向右) \\ ΔQ(状态(s)&:0,动作(a):向右) \\ &= R(状态(s):0,动作(a):向右)+γ max Q(状态(s):1,动作(a))) -Q ( 状态(s):0,动作(a):向右) \\ ΔQ(状态(s)&:0,动作(a):向右) \\ &=-1+0.9 \\ &*max(Q(状态(s):1,动作(a):向左),Q(状态(s):1,动作 (a):向右),Q( 状态(s):1,动作 \\ &(a):向下))- Q (状态(s):0,动作(a):向右) \\ ΔQ(状态(s)&:0,动作(a):向右)\\ &=-1+0.9*0-0= -1 \\ New Q(状态(s)&:0,动作(a):向右)=0+0.1*(-1)=-0.1 \end{aligned} \end{align} \end{split}\]多智能体强化学习算法中智能体的起点和终点是根据梁柱内的钢筋间距决定的。且障碍物的位置是由上一个训练步骤中,其他智能体的路径所决定的。这也就是说,在一次训练任务中,起点和终点的位置均保持不变,但障碍物是由环境内所有智能体的路径所产生,因此随着训练任务的进行,环境内的障碍物逐渐增多。由于在每次任务中,障碍物的位置可能不一致,因此智能体需要学习策略以应对未知的情况,如图5-9所示。
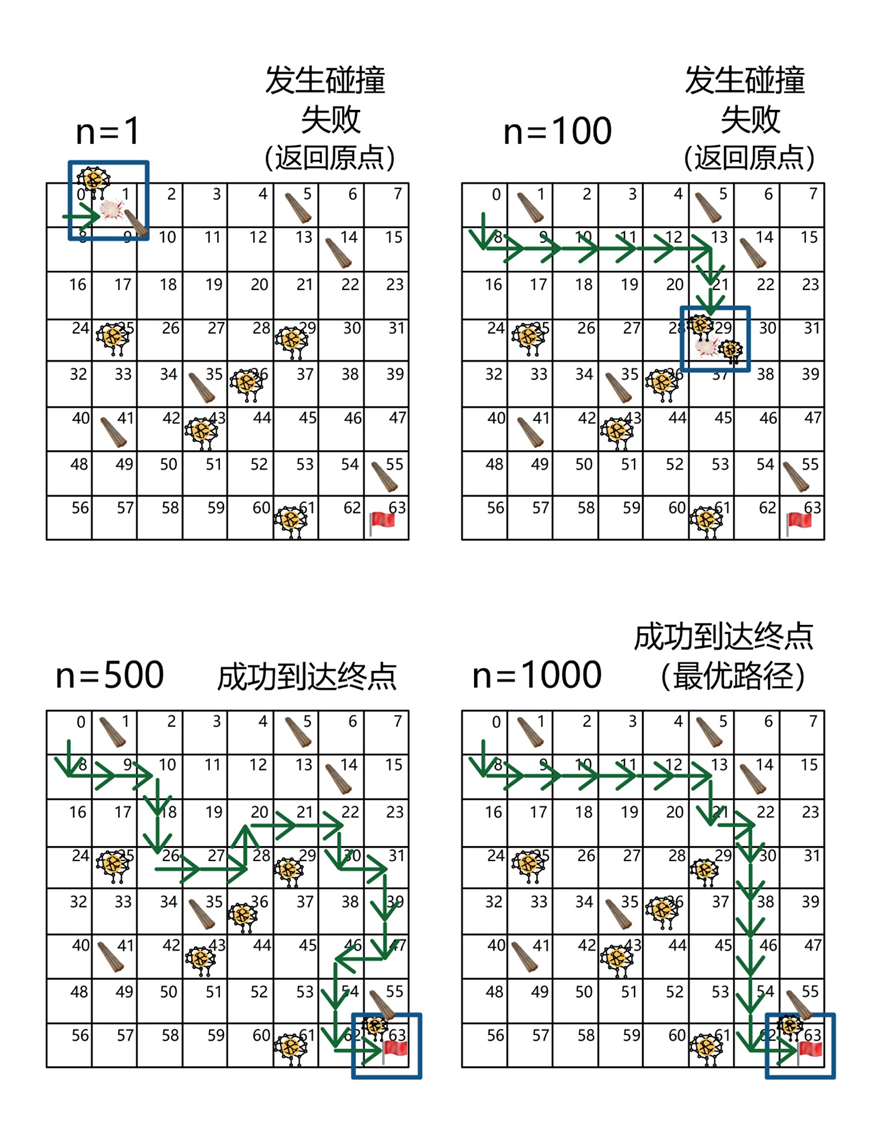 图 5-9 智能体学习过程释义
图 5-9 智能体学习过程释义