3.3.2. 模型训练#
模型训练一共分为三个步骤:1. 创建网络模型,此处我们将采用两种方法创建。2. 定义训练函数,设置一些必要的显示参数。3. 定义功能函数与训练,设定损失函数与优化函数等功能函数并进行训练。下面我们将逐步讲解如何创建网络并进行训练。
(1)创建网络模型
这一部分我们主要通过两种方式创建ResNet18网络模型。第一种是直接使用PyTorch框架中内嵌的ResNet18包,第二种则是通过PyTorch框架自行编译ResNet18模型。
第一种:直接使用ResNet18内嵌包
1import torch
2from torch import nn
3from torchvision import models
4
5device = "cpu"
6if torch.cuda.is_available():
7 device = "cuda"
8# 使用预训练模型,随着torchvision 版本变动,该函数实际使用方式在发生变化
9model = models.resnet18(pretrained=True)
10# 仅取卷积层
11fc_inputs = model.fc.in_features
12# 载入的resnet18不包含后续的全连接层,需要根据自己项目需求写入
13model.fc = nn.Sequential(
14 # 全连接层,接256个神经元
15 nn.Linear(fc_inputs, 256),
16 nn.ReLU(),
17 # 全连接层,接输出
18 nn.Linear(256, 6)
19)
20model = model.to(device)
在直接使用ResNet18时,我们不仅可以加载ResNet18的网络框架,还可以选择是否载入预训练权重。当pretrained=True时,则表示我们希望载入预训练权重,并将其作为初始权重进行后续训练。预训练数据集大多采用ImageNet数据,在选择是否载入预训练权重时,可以观察自己的训练数据和预训练数据的特征相似性。如果数据特征相似,采用预训练权重可以加快模型收敛速度,节省训练时间,使用预训练权重有时也称为迁移学习。如果数据特征相差较多,则不建议使用预训练权重。对于上述网络,我们在输出端定义了两个全连接层,以提高模型的非线性表达能力。可观察以下程序每次运行后的数据结构信息。
summary(model, (3, 224, 224))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
……
……
ReLU-62 [-1, 512, 7, 7] 0
Conv2d-63 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
ReLU-65 [-1, 512, 7, 7] 0
BasicBlock-66 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0
Linear-68 [-1, 256] 131,328
ReLU-69 [-1, 256] 0
Linear-70 [-1, 6] 1,542
================================================================
Total params: 11,309,382
Trainable params: 11,309,382
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 62.79
Params size (MB): 43.14
Estimated Total Size (MB): 106.51
TIPS:迁移学习
迁移学习是指以学习完毕的权重作为基础,通过替换不同的最终输出层来进行学习的方法,即将学习完毕的模型中,最后的输出层替换成能够对应到我们现有数据的输出层,并使用我们少量的数据对被替换的输出层的连接参数(以及位于其前面的若干层网络的连接参数)进行重新学习,而位于输入层附近的连接参数则仍然继续保持使用之前训练好的参数值不变。
迁移学习的优点是即使我们数据的数量很少,也能比较容易地实现深度学习。此外,如果对位于输入层附近网络层的连接参数也进行更新,则称为微调(Fine Tuning)。
第二种:通过PyTorch框架自行编译ResNet18模型 ResNet18由两种不同的残差单元组成,分别为CommonBloc和SpecialBlock,要搭建ResNet18需要先编译这两个基础模块。这两个残差单元有很多相似之处,我们对照图3-6,通过代码来实现残差单元的功能。
1from torch import nn, functional as F
2
3
4class CommonBlock(nn.Module):
5 def __init__(self, in_channel, out_channel, stride):
6 super(CommonBlock, self).__init__()
7 # 第一次卷积操作参数设置
8 self.conv1 = nn.Conv2d(in_channel,
9 out_channel,
10 kernel_size=3,
11 stride=stride,
12 padding=1,
13 bias=False)
14 self.bn1 = nn.BatchNorm2d(out_channel)
15 # 第二次卷积操作参数设置
16 self.conv2 = nn.Conv2d(out_channel,
17 out_channel,
18 kernel_size=3,
19 stride=stride,
20 padding=1,
21 bias=False)
22 self.bn2 = nn.BatchNorm2d(out_channel)
23
24 def forward(self, x):
25 """
26 调用内部功能函数,对输入x进行处理
27 Args:
28 x:
29
30 Returns:
31
32 """
33 # 将初始输入x直接赋给identity
34 identity = x
35 # 对输入x进行第一次卷积操作并激活
36 x = F.relu(self.bn1(self.conv1(x)), inplace=True)
37 # 第二次卷积操作
38 x = self.bn2(self.conv2(x))
39 # 将第二次卷积操作的输出与未经处理的输入相加
40 x += identity
41 # 激活后返回输出结果
42 return F.relu(x, inplace=True)
以上步骤可简要表述为:CommonBloc首先将输入x的值直接赋给identity(没有处理),然后将x接连进行第一次卷积操作(卷积标准化激活)第二次卷积操作(卷积标准化)输入(没有处理)+输出(操作处理)激活,最后返回输出结果。
1from torch import nn, functional as F
2
3
4class SpecialBlock(nn.Module):
5 def __init__(self, in_channel, out_channel, stride):
6 super(SpecialBlock, self).__init__()
7 # 旁支卷积,负责改变输入x维度
8 self.change_channel = nn.Sequential(
9 nn.Conv2d(in_channel,
10 out_channel,
11 kernel_size=1,
12 stride=stride[0],
13 bias=False),
14 nn.BatchNorm2d(out_channel)
15 )
16 # 第一次卷积操作参数设置
17 self.conv1 = nn.Conv2d(in_channel,
18 out_channel,
19 kernel_size=3,
20 stride=stride[0],
21 padding=1,
22 bias=False)
23 self.bn1 = nn.BatchNorm2d(out_channel)
24 # 第二次卷积操作参数设置
25 self.conv2 = nn.Conv2d(out_channel,
26 out_channel,
27 kernel_size=3,
28 stride=stride[1],
29 padding=1,
30 bias=False)
31 self.bn2 = nn.BatchNorm2d(out_channel)
32
33 def forward(self, x):
34 """
35 # 调用内部功能函数,对输入x进行处理
36 Args:
37 x:
38
39 Returns:
40
41 """
42 # 输入x经旁支卷积处理后赋给identity
43 identity = self.change_channel(x)
44 # 对输入x进行第一次卷积操作并激活
45 x = F.relu(self.bn1(self.conv1(x)), inplace=True)
46 # 第二次卷积操作
47 x = self.bn2(self.conv2(x))
48 # 将第二次卷积操作的输出x与经旁支卷积处理后的identity相加
49 x += identity
50 # 激活后返回输出结果
51 return F.relu(x, inplace=True)
以上步骤可简要表述为:SpecialBlock首先将输入x经旁支卷积处理后赋给identity,然后将x接连进行以下操作:第一次卷积操作(卷积->标准化->激活)第二次卷积操作(卷积->标准化)->经处理后的输入、输出相加->激活,最后返回输出结果。
上面我们已经将两个残差单元写成了标准模块,需要再次强调的是,CommonBlock残差单元不改变输入维度,而SpecialBlock残差块将通道数翻倍而宽高减半。接下来,我们将通过残差单元的调用实现ResNet18网络结构,具体代码如下。
1import torch
2from torch import nn
3
4from chapter_3_3_2_02 import CommonBlock
5from chapter_3_3_2_03 import SpecialBlock
6
7
8class ResNet18(nn.Module):
9 def __init__(self, classes_num=6):
10 super(ResNet18, self).__init__()
11 # 池化后 —> [batch, 64, 56, 56]
12 self.prepare = nn.Sequential(
13 # 预卷积操作参数设置
14 nn.Conv2d(3, 64, 7, 2, 3),
15 nn.BatchNorm2d(64),
16 # 预卷积操作后—> [batch, 64, 112, 112]
17 nn.ReLU(inplace=True),
18 # 最大池化参数设置
19 nn.MaxPool2d(3, 2, 1)
20 )
21 self.layer1 = nn.Sequential(
22 # 第一个残差单元,—> [batch, 64, 56, 56]
23 CommonBlock(64, 64, 1),
24 # 第二个残差单元,—> [batch, 64, 56, 56]
25 CommonBlock(64, 64, 1)
26 )
27 self.layer2 = nn.Sequential(
28 # 第三个残差单元,—> [batch, 128, 28, 28]
29 SpecialBlock(64, 128, [2, 1]),
30 # 第四个残差单元,—> [batch, 128, 28, 28]
31 CommonBlock(128, 128, 1)
32 )
33 self.layer3 = nn.Sequential(
34 # 第五个残差单元,—> [batch, 256, 14, 14]
35 SpecialBlock(128, 256, [2, 1]),
36 # 第六个残差单元,—> [batch, 256, 14, 14]
37 CommonBlock(256, 256, 1)
38 )
39 self.layer4 = nn.Sequential(
40 # 第七个残差单元,—> [batch, 512, 7, 7]
41 SpecialBlock(256, 512, [2, 1]),
42 # 第八个残差单元,—> [batch, 512, 7, 7]
43 CommonBlock(512, 512, 1)
44 )
45 self.pool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
46 # 通过一个自适应均值池化—> [batch, 512, 1, 1]
47 self.fc = nn.Sequential(
48 # 全连接层,512—>256
49 nn.Linear(512, 256),
50 nn.ReLU(inplace=True),
51 # 六分类,256—> classes_num == 6
52 nn.Linear(256, classes_num)
53 )
54
55 def forward(self, x):
56 """
57 使用ResNet18对输入x进行处理,输入x—> [batch, 3, 224, 224]
58
59 Args:
60 x:
61
62 Returns:
63
64 """
65 x = self.prepare(x)
66 x = self.layer1(x)
67 x = self.layer2(x)
68 x = self.layer3(x)
69 x = self.layer4(x)
70 x = self.pool(x)
71 x = x.reshape(x.shape[0], -1)
72 x = self.fc(x)
73 # 返回网络输出结果—>[batch, 6]
74 return x
75
76
77device = "cpu"
78if torch.cuda.is_available():
79 device = "cuda"
80model = ResNet18()
81model = model.to(device)
通过上面的代码,我们已经明确了ResNet18的网络结构,也通过程序详细介绍了输入x的维度变化过程。同样观察模型的结构:
summary(model, (3, 224, 224)) # 输出模型结构
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,472
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
……
……
Conv2d-46 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-47 [-1, 512, 7, 7] 1,024
Conv2d-48 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-49 [-1, 512, 7, 7] 1,024
CommonBlock-50 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-51 [-1, 512, 1, 1] 0
Linear-52 [-1, 256] 131,328
ReLU-53 [-1, 256] 0
Linear-54 [-1, 6] 1,542
================================================================
Total params: 11,309,446
Trainable params: 11,309,446
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 51.30
Params size (MB): 43.14
Estimated Total Size (MB): 95.02
从上述两个模型的结构可以看出,两个网络输出维度的变化相同,且两个网络框架完全相同。后续的训练测试,我们将以第一种为例进行讲解。
(2)定义训练函数
创建网络模型后,需要定义训练函数,通过计算损失,实现网络参数的训练。同时,为了观察训练细节,还需要输出每批次训练的损失及一个循环完成的准确率、时间等信息。定义如下函数:
1import os
2import datetime
3
4import torch
5from torch.utils import tensorboard
6
7from chapter_3_3_2_01 import device
8from chapter_3_3_1_05 import dataloaders
9from chapter_3_3_1_02 import dataset_sizes
10
11
12def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
13 if not os.path.exists("model"):
14 os.mkdir("model")
15 model_save_path = os.path.join("model", "best.pt")
16
17 # 创建"logs"文件夹,并以"训练开始日期-时间"为子文件名存储训练数据
18 time_path = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
19 writer = tensorboard.SummaryWriter(os.path.join('logs', time_path))
20 # 初始化最优准确率
21 best_acc = 0.0
22 for epoch in range(num_epochs):
23 # 记录开始时间
24 since = datetime.datetime.now()
25 # 存储损失值
26 loss_both = {
27 }
28 # 存储准确率
29 acc_both = {
30 }
31 # 每一个epoch都包含训练集和测试集
32 for phase in ['train', 'val']:
33 if phase == 'train':
34 model.train()
35 else:
36 model.eval()
37 # 初始化损失值
38 running_loss = 0.0
39 # 初始化准确率
40 running_corrects = 0
41
42 # 开始循环训练,每次从dataloaders读取bach_size个图片和标签。
43 for loop_i, datas in enumerate(dataloaders[phase]):
44 inputs, labels = datas
45 inputs = inputs.to(device)
46 labels = labels.to(device)
47 # 初始化优化梯度
48 optimizer.zero_grad()
49 # 训练模式进行如下操作
50 with torch.set_grad_enabled(phase == 'train'):
51 outputs = model(inputs)
52 _, preds = torch.max(outputs, 1)
53 # 最后输出的6个结果为六个类别的概率,取最大概率的位置索引赋给preds
54 # 计算输出与标签的损失
55 loss = criterion(outputs, labels)
56 # 打印每个bach_size损失值
57 print(f"{phase}:{loop_i},loss:{loss}")
58 # 训练模式下需要进行反向传播和参数优化
59 if phase == 'train':
60 # 训练模式下计算损失
61 loss.backward()
62 # 训练模式下参数优化方法
63 optimizer.step()
64 # 统计损失和准确率
65 running_loss += loss.item() * inputs.size(0)
66 running_corrects += torch.sum(preds == labels.data)
67 # 计算一个epoch损失值
68 epoch_loss = running_loss / dataset_sizes[phase]
69 # 计算一个epoch准确率
70 epoch_acc = running_corrects.double() / dataset_sizes[phase]
71
72 # 将每个epoch损失值存入字典
73 loss_both[phase] = epoch_loss
74 # 将每个epoch准确率存入字典
75 acc_both[phase] = epoch_acc
76 # 调整学习率
77 scheduler.step()
78 # 计算一个epoch时间
79 time_elapsed = datetime.datetime.now() - since
80 print(
81 f"time :{time_elapsed}, epoch :{epoch + 1}, "
82 f"loss: {loss_both['train']}, acc :{acc_both['train']}"
83 f"val loss:{loss_both['val']},val acc: {acc_both['val']}"
84 )
85 # 训练完一个epoch后打印: time :xx, epoch :x, loss: xx,
86 # acc :xx val loss:xx, val acc: xx
87 if acc_both["val"] > best_acc:
88 best_acc = acc_both["val"]
89 torch.save(model.state_dict(), model_save_path)
90 # 将当前epoch的训练结果与过去最好的结果进行比较,如果更好,则在对应地址下更新参数
91 # 如果没有变好,则不保存参数。
92
93 # 写入tensorboard 供查看训练过程
94 writer.add_scalars("epoch_accuracy", tag_scalar_dict=acc_both,
95 global_step=epoch)
96 writer.add_scalars("epoch_loss", tag_scalar_dict=loss_both,
97 global_step=epoch)
98
99 # 将训练的参数载入模型
100 if os.path.exists(model_save_path):
101 model.load_state_dict(torch.load(model_save_path))
102 model.eval()
103 # 返回带训练参数的模型
104 return model
我们在训练函数中描述了如何通过网络模型的输出计算损失和准确率,并在每一个bach_size累计损失和准确率,以便计算训练完成一个epoch后评价指标。同时还对每一次epoch的效果进行对比,来判断是否保存当前训练参数。接下来就是定义功能函数与训练。
(3)定义功能函数与训练
在上述学习中我们已经准备好训练数据,并创建好用于训练的模型,同时还定义了训练函数,接下来,需要给训练函数中使用的功能函数进行赋值。训练函数中用到的功能函数有损失函数、优化函数和学习率优化函数,损失函数使用交叉熵损失函数,优化方法使用Adam,学习率优化为lr_scheduler.StepLR。定义好功能函数后便可以调用训练函数开始训练。
1import torch
2from torch import nn, optim
3
4from chapter_3_3_2_01 import model, device
5from chapter_3_3_1_02 import label_weight
6from chapter_3_3_2_05 import train_model
7
8loss_weight = torch.FloatTensor(label_weight).to(device)
9criterion = nn.CrossEntropyLoss(weight=loss_weight)
10# 定义优化函数,adam优化函数
11optimizer = optim.Adam(model.parameters(), lr=1e-2)
12# 调整学习率,40个epoch学习率衰减0.1
13exp_lr_scheduler = optim.lr_scheduler.StepLR(optimizer,
14 step_size=40,
15 gamma=0.9)
16
17# 调用训练函数,开始训练
18model_ft = train_model(model,
19 criterion,
20 optimizer,
21 exp_lr_scheduler,
22 num_epochs=1)
在深度学习框架中有多种损失函数和优化函数可以调用,我们可以根据项目类型和需求自行选择。其中batch_size=128,epoch=1时观察输出结果如下:
train:0,loss:1.7950094938278198
train:1,loss:1.785098671913147
………
train:349,loss:1.4534833431243896
train:350,loss:1.3650745153427124
val:0,loss:2.0289664268493652
val:1,loss:1.7434654235839844
………
val:86,loss:1.8223122358322144
val:87,loss:1.6298279762268066
time :0:07:53.236890, epoch :1, loss: 1.4867162976860375, acc :0.2642463952218582val loss:1.881824580820558,val acc: 0.07762231530166652
训练集有44871张图片,bach_size设置为128,可以计算一个epoch的loop_i为351,则训练到train:350停止。一个epoch训练完成后,在尾行输出训练时间、训练集和测试集的损失和准确率。同时还会在程序文件根目录生成model文件夹,并在其中保存训练参数best.pt。还会生成logs文件夹,并在其中保存训练过程信息,可以打开观察训练过程曲线。
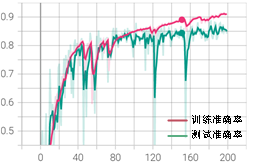
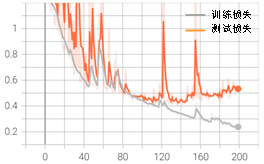
学到这里,我们的模型已经可以正常运行了,但是想要获得一个好的结果,在训练之前还需要进行一些调参,这是优化模型最简单的方法。在深度学习中一般有两类参数:一类需要从数据中学习和训练得到,称为模型参数(Parameter),比如本项目中卷积参数和全连接参数。还有一类则是模型的调优参数(tuning parameters),称为超参数(Hyperparameter)。比如,迭代次数epoch,批量大小batch_size等。我们常常需要根据现有的经验对其设定“正确”的值。对于迭代次数epoch来说,设置过小,会导致训练不充分,泛化能力差;过大,可能训练过度,导致过拟合。batch_size设置过小会导致每次计算的梯度不稳定,训练震荡较大,难以收敛;过大则容易内存溢出,一般设置为2的n次方。最终需综合考虑数据集量、特征分布、网络结构、设备等多方面因素对上述参数进行调整,以达到最优的分类性能。我们根据设备和数据集情况首先选取训练参数batch_size = 512、epoch = 200、数据集分割比为0.2、初始学习率0.01,衰减率0.9,衰减间隔40个epoch。完整代码可扫描二维码下载,训练结果如图3-11所示。
代码下载
需适配线上版本做改动