5.3.4. 创建训练函数#
训练函数定义了多智能体训练的总体框架。在每个轮次(epoch)的训练中,智能体从迷宫中的指定的位置开始,试图到达目标,同时避免障碍物。智能体使用 Q-learning 根据它在每个轮次中获得的奖励和惩罚来更新策略。同时记录并绘制每轮训练的总奖励、总步数和成功率。
from maze_env import Maze
from RL_brain import QLearningTable
import matplotlib.pyplot as plt
jList = []
rList = []
success_rate = []
rAll = 0
def update():
n = 400
for episode in range(n):
print('episode=', episode)
# 初始化智能体的观测状态值
observation1 = env.reset1(episode, n)
observation2 = env.reset2(episode, n)
observation3 = env.reset3(episode, n)
# 初始化奖励和成功记录
rAll = 0
j = 0
success_count = 0
flag1 = 0
flag2 = 0
flag3 = 0
while True:
if episode >= n - 10:
env.render()
# 智能体根据状态观测值选择动作
j += 1
action1 = RL.choose_action(str(observation1), episode, n)
action2 = RL.choose_action(str(observation2), episode, n)
action3 = RL.choose_action(str(observation3), episode, n)
# 智能体采取行动,获得来自环境的观察和奖励
observation_1, reward1, done1 = env.step1(action1, episode, n)
observation_2, reward2, done2 = env.step2(action2, episode, n)
observation_3, reward3, done3 = env.step3(action3, episode, n)
# 智能体进行学习
RL.learn(str(observation1), action1, reward1, str(observation_1))
RL.learn(str(observation2), action2, reward2, str(observation_2))
RL.learn(str(observation3), action3, reward3, str(observation_3))
if reward1 == -1:
flag1 = 1
if reward2 == -1:
flag2 = 1
if reward3 == -1:
flag3 = 1
# 更新智能体的观测
observation1 = observation_1
observation2 = observation_2
observation3 = observation_3
rAll += reward1 + reward2 + reward3
# 定义训练循环结束的条件
if done1 == True and reward1 == 1 and flag1 == 0:
success_count += 1
flag1 = 1
if done2 == True and reward2 == 1 and flag2 == 0:
success_count += 1
flag2 = 1
if done3 == True and reward3 == 1 and flag3 == 0:
flag3 = 1
success_count += 1
if done1 and done2 and done3:
break
rList.append(rAll)
# print( 'total reward=',rAll)
jList.append(j)
# print('total step=',j)
success_rate.append(success_count / 3)
# 训练结束,关闭环境
print('game over')
env.destroy()
if __name__ == "__main__":
# 初始化环境和Q-learning
env = Maze()
RL = QLearningTable(actions=list(range(env.n_actions)))
# 开始训练
env.after(100, update)
env.mainloop()
# 可视化训练结果
plt.figure()
plt.plot(rList, label='Total Reward')
plt.plot(jList, label='Total Steps')
plt.xlabel('Episode')
plt.legend()
plt.figure()
average_reward = []
for i in range(len(rList)):
average_reward.append(rList[i] / jList[i])
plt.plot(average_reward, label='Average Reward')
plt.legend()
plt.figure()
plt.plot(success_rate, label='Success Rate')
plt.legend()
plt.show()
在经过400轮训练之后,我们记录并可视化了环境中多个智能体的平均成功率,平均奖励,每轮训练中的总行动步数和总奖励,如图5-11所示。可以发现,随着训练的进行,智能体的平均成功率和平均奖励逐步上升,并趋于稳定。在训练开始时,曲线波动较大,这是由于我们设置了较大的贪心率以鼓励智能体多采用随机动作进行探索。随着训练的进行,贪心率逐步下降,智能体逐渐倾向于选择Q-Table中数值最大的动作,训练曲线也逐渐趋于稳定,平均成功率达到100%,平均奖励接近0.4。代码链接
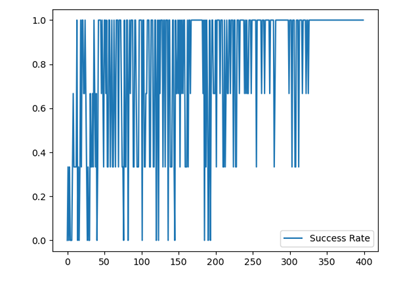
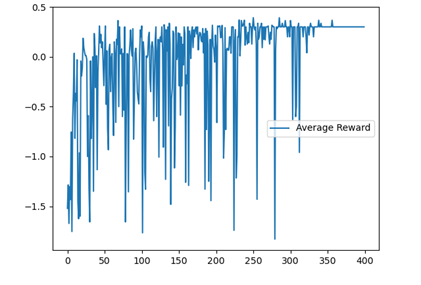
图 5-11 多智能体强化训练结果可视化