5.2.1. 强化学习智能体设计#
强化学习智能体组成
每个智能体由三个模块组成:(1)状态(State):对环境的感知,用于保存和表示当前智能体的状态;(2)动作(Action):用于表示该状态下可选择的行为;(3)奖励(Reward):用于表示来自环境的反馈。在智能体执行动作、从环境收到反馈后,智能体会根据反馈进行策略调整。在获得奖励(积极反馈)的情况下,智能体将学习到在某个状态下执行的动作将导致良好的结果。因此,经过训练,强化学习将学会状态向量S、动作向量A和奖励向量R之间的映射关系。
智能体状态模块
多智能体强化学习系统指多个智能体如何以梁或柱的一端为起点导航到另一端的终点问题。每个智能体配备感知环境的传感器,这些传感器可以探测周边环境的情况。同时,传感器检测的状态信息包括障碍(已排布的钢筋,即其他智能体的路径)检测、其他智能体位置检测以及目标点在当前位置下的方位检测。例如,在图5-3中,状态信息表示在智能体的正前方检测到了障碍物(钢筋),编码为(0,0,1,0,0);另一个智能体位于智能体的左前方,编码为(0,1,0,0,0);目标(红旗)位于智能体的右前方,编码为(0,1,0,0,0,0,0,0)。对于每一个方向的传感器反馈回来的状态信息,可由S_i=1/〖 d〗i进行计算。公式中的〖 d〗 i表示在i方向上智能体与障碍物、其他智能体、目标点或构件边界的距离。如果在该方向上未发现任何障碍物、其他智能体、目标点或者构件边界,则S_i被定义为0。在没有先验知识(障碍物和目标的三维坐标信息)的情况下,每个智能体都配备了它所在环境的局部视野。
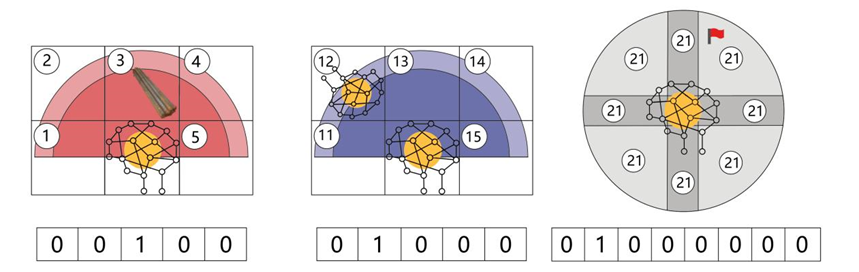 图 5-3 智能体状态定义
图 5-3 智能体状态定义
智能体动作模块
如图5-4所示,在多智能体强化学习系统中,在每个离散步长中,智能体可以选择五个可能的动作之一,即向左、向前、向右、向上和向下移动。
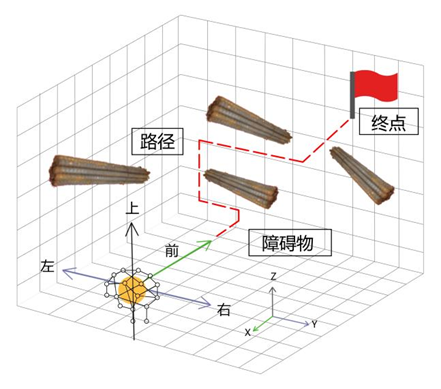 图 5-4 智能体动作定义
图 5-4 智能体动作定义
智能体奖惩模块
在多智能体强化学习算法中,基于钢筋的设计规范和构造约束要求,设计了奖励、惩罚和一些特定策略,如图5-5和表5-1所示。在实验中,智能体无需在执行每个动作之后都从环境得到相关的奖励。这是因为在现实世界中,智能体的目标可能被隐藏或者在现有的状态下不可见,所以可能很难到达。表5-1特别说明了奖惩策略:
当智能体到达目标且不与障碍物发生碰撞,同时不超过规定的训练时间时,奖励为:+1。
当智能体选择的行为使智能体靠近目标点,为了鼓励智能体往目标点继续前进,奖励为:+0.4
当智能体与障碍物(钢筋)发生碰撞,或与其他智能体及其路径发生碰撞,或超过规定的训练时间时,惩罚为:-1。
当智能体与其他智能体或其他智能体的路径之间的距离小于特定范围(1.5倍钢筋直径),惩罚为:-1,以确保钢筋之间的间距满足要求。
当智能体选择的动作(左,右,上,下)导致路径发生弯曲,惩罚为:-0.5,以保证智能体的路径尽可能为直线,因为钢筋除在发生碰撞需要弯起时均应为直线。
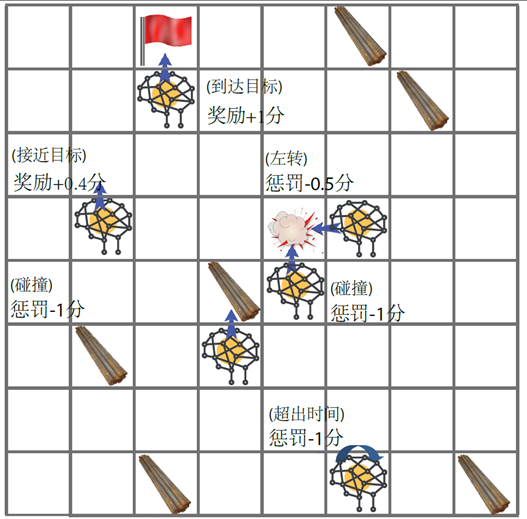 图 5-5 智能体奖励惩罚策略
图 5-5 智能体奖励惩罚策略
智能体奖惩策略 |
|
|---|---|
智能体无碰撞且抵达终点 |
+1.0 |
智能体与目标点的距离减小 |
+0.4 |
智能体与其他智能体路径发生碰撞 |
-1.0 |
智能体与其他智能体发生碰撞 |
-1.0 |
智能体与其他智能体的路径小于设定范围 |
-1.0 |
智能体超过设定的训练时间 |
-1.0 |
智能体选择转弯动作(左,右,上,下) |
-0.5 |